动手实战人工智能
一直想深入动手实战一下人工智能的案例,终于发现大佬有篇十分详细的文章,自己也跟着进行学习一下
入门机器学习的过程中,如果你只会调包,而不深入原理,可能连参数的作用都看不懂,更别说调参了。如果你只会理论,而不会实践。可能连最简单的模型都写不出来。因此,我希望能够帮助你,既能够理解原理,又能够实践应用。
动手实战人工智能系列教程,希望从监督学习开始,带你入门机器学习和深度学习。我尝试剖析和推导每一个基础算法的原理,将数学过程写出来,同时基于 Python 代码对公式进行实现,做到公式和代码的一一对应。与此同时,我也会利用主流的开源框架重复同样的过程,帮助读者看出手动实现和主流框架实现之间的区别。

监督学习回归
环境搭建
相关介绍
所有的内容均使用 Jupyter Notebook 书写并运行,便于理解和复现。你可以使用本地 Jupyter Notebook 或者 Google Colab 运行代码。
除单独说明的章节外,所有代码均在 Python 3.10 环境下运行通过。一般情况下,代码可以在相关 package 的主流版本下运行,如果运行报错,可以尝试单独安装以下版本,部分库的安装也会在相应的章节中有提示。由于依赖较多且个别库的依赖之间存在版本冲突,所以不提供统一的
requirements.txt文件。numpy == 1.26.1
scipy == 1.11.3
pandas == 2.1.2
seaborn == 0.13.0
matplotlib == 3.8.1
scikit-learn == 1.3.2
statsmodels == 0.11.0
jieba == 0.42.1
gensim == 4.3.2
hdbscan == 0.8.33
graphviz == 0.20.1
mlxtend == 0.23.0
tensorflow == 2.14.0
nltk == 3.8.1
flair == 0.13.0
onnx == 1.15.0
深度学习的章节,对数据量和网络结构进行了简化,绝大部分都可以无需 GPU 运行,便于更多人学习。需要 GPU 的内容会在相应的章节中有说明。
因跨域设置,部分数据集 Pandas 可能无法通过链接直接加载,你可以手动复制链接到浏览器下载数据集到本地后,再使用本地路径进行加载。
环境配置
Mac Os 14.1.1 |
安装pyenv
安装相对简单不进行过多描述,可以根据自己电脑情况自行安装
pyenv local 3.10.0 //使文件目录切换为3.10.0版本 |
生效后在本地创建requirements.txt 放入上文相关依赖
python3 -m pip install -r requirements.txt |
由于时间原因直接安装依赖会产生错误给出最新requirements 等待安装完毕即可
|
机器学习综述及示例
介绍
机器学习是概率论、统计学、计算理论、最优化方法、以及计算机科学组成的交叉学科,其主要的研究对象是如何从经验中学习并改善具体算法的性能。本次实验将介绍机器学习的概念及相关细分类别。
机器学习介绍
机器学习 Machine Learning 是人工智能的一个分支,其核心构成为机器学习算法,并通过从数据中获取经验来改善自身的性能。机器学习的诞生时间很早,但随着近些年计算机技术及相关领域的迅速发展,机器学习再一次变得热闹起来。
想要了解什么是机器学习?我们从机器学习的定义开始。其中,一个十分经典的定义来自于计算机科学家 TOM M.Mitchell 于 1997 年出版的《机器学习》专著,这句话的原文如下:
Note
A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.
对于某类任务 T 和性能度量 P ,如果一个计算机程序在 T 上以 P 衡量的性能随着经验 E 而自我完善,那么我们称这个计算机程序在从经验 E 学习。
你可能会觉得上面这句定义太学术,甚至读了多遍都没有理解到其中要准确表达的意思。简单来讲,这句话强调的是「学习」,而核心意义就是:计算机程序通过累计经验来获得性能的提升。
其中,计算机程序的核心就是我们所说的「机器学习算法」,而机器学习算法则来源于基础数学理论和方法。有了可以自主学习的算法,程序就可以从训练数据中自动分析获得规律,并利用规律对未知数据进行预测。
机器学习&深度学习&人工智能
我们经常会从媒体报道及学术资料中看到机器学习、深度学习、人工智能三个不同的名词,但往往又捉摸不透几者之间的关系。它们之间是包含,交叉,还是完全独立呢?
这里,我们引用资深科技记者 Michael Copeland 文章中的部分观点进行解释。三者中,最先出现的概念是人工智能,它是于 1956 年由 John McCarthy 提出。当时,人们渴望设计出一种「能够执行人类智能特征任务的机器」。
之后,研究人员构思出机器学习的概念,而机器学习的核心是寻求实现人工智能的方法。于是就出现了朴素贝叶斯、决策树学习、人工神经网络等众多机器学习方法。其中,人工神经网络(ANN)是模拟大脑生物结构的一种算法。
再到后来,就出现了深度学习。深度学习的关键在于建立具有更多神经元、更多层级的深度神经网络。我们发现,这种深度神经网络的学习效果在图像辨识等方面甚至超越了人类。
所以,关于上述 3 个概念,可以总结出如下所示的关系图。其中,机器学习是实现人工智能的手段,而深度学习只是机器学习中的一种特定方法。
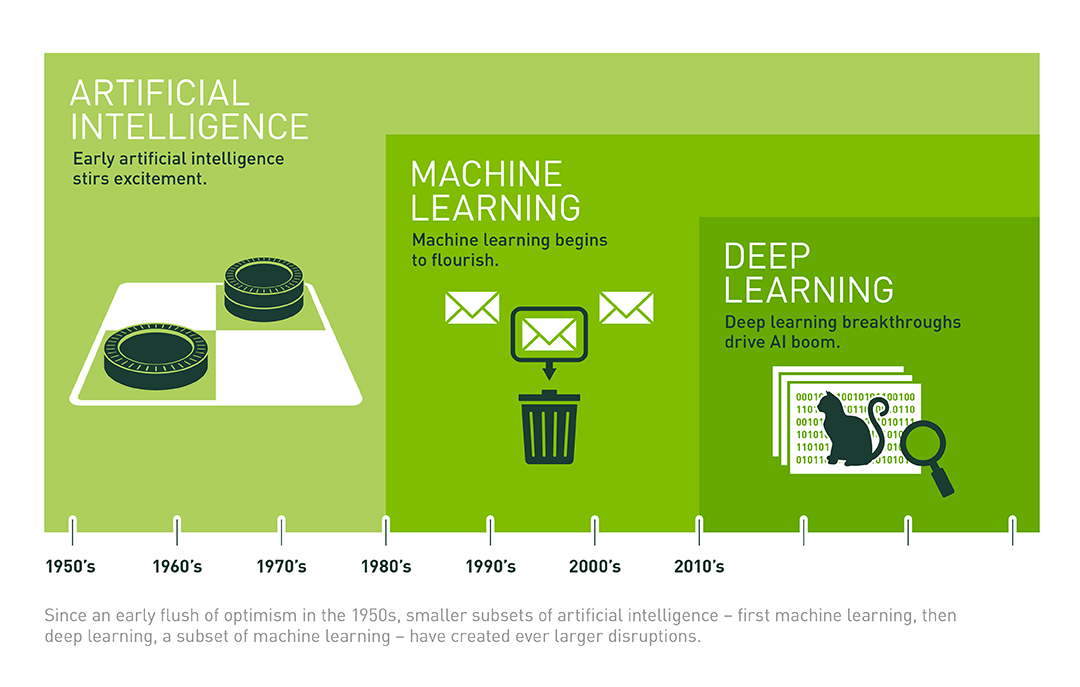
目前,我们通常所说的「机器学习」大致包含四大类:监督学习,英文为 Supervised Learning;无监督学习,英文为 Unsupervised Learning;半监督学习,英文为 Semi-supervised Learning;强化学习,英文为 Reinforcement Learning。
本次课程中,我们重点学习监督学习和无监督学习相关的方法。其中,监督学习通常解决分类和回归问题,无监督学习主要解决聚类问题,其又被细分为数十种不同的算法。
本次课程中,我们重点学习监督学习和无监督学习相关的方法。其中,监督学习通常解决分类和回归问题,无监督学习主要解决聚类问题,其又被细分为数十种不同的算法。
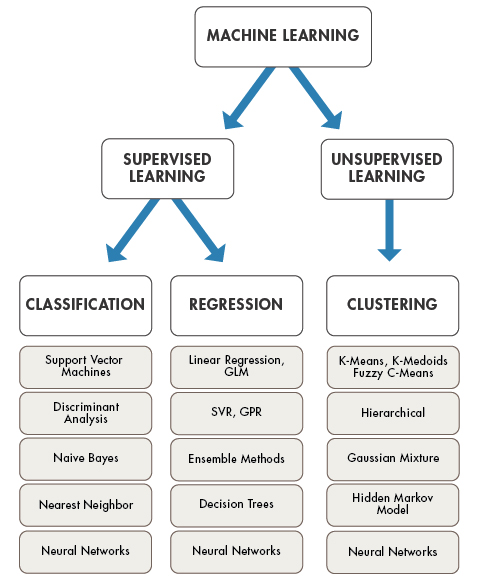
接下来,我们重点了解监督学习和无监督学习的概念,以及分类、回归、聚类到底是怎样一回事。
监督学习方法
要想了解监督学习,首先从定义展开。
关于 监督学习 的定义,这里引用著名机器学习专家 Mehryar Mohri 在其专著 Foundations of Machine Learning 中的叙述:
Note
Supervised learning is the machine learning task of learning a function that maps an input to an output based on example input-output pairs. It infers a function from labeled training data consisting of a set of training examples.
监督学习是基于示例输入-输出数据对,在输入和输出数据之间建立数学函数的机器学习任务,而该数学函数来源于对有标签训练数据集的学习过程。
解释一下这句话中的几个关键词。示例输入和输出数据对其实就是训练数据集,而输入指的是训练数据集中的特征变量,输出则是标签。而建立数学函数,实际就是训练机器学习预测模型。这句话,其实就是一个典型的机器学习过程。而监督学习的关键在于,这里提供的训练数据集有标签。
监督学习示例
为了更好地理解上面关于监督学习的定义,下面举一个判断花朵种类的例子。
如图所示,训练数据集给出了 3 种不同花朵的花瓣长度特征(训练集特征),我们已经知道这 3 朵花的种类 A,B,C(标签)。那么,对于一朵未知种类的花,就可以根据它的花瓣长度(测试样本特征)来判断它所属种类(测试样本标签)。下图中,未知花朵判断成 B 类肯定更合适一些。
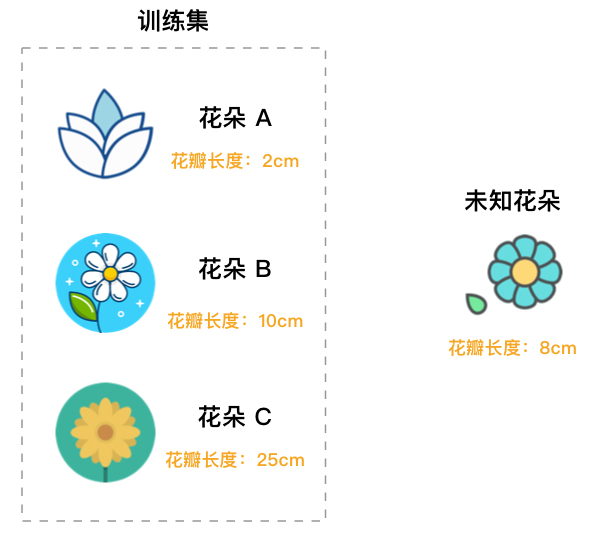
综上,监督学习中的「监督」就体现在训练集具有「标签」。就像上图中,我们给出了已知种类的花,对于未知种类的花就根据特征去比较就可以了。
分类与回归
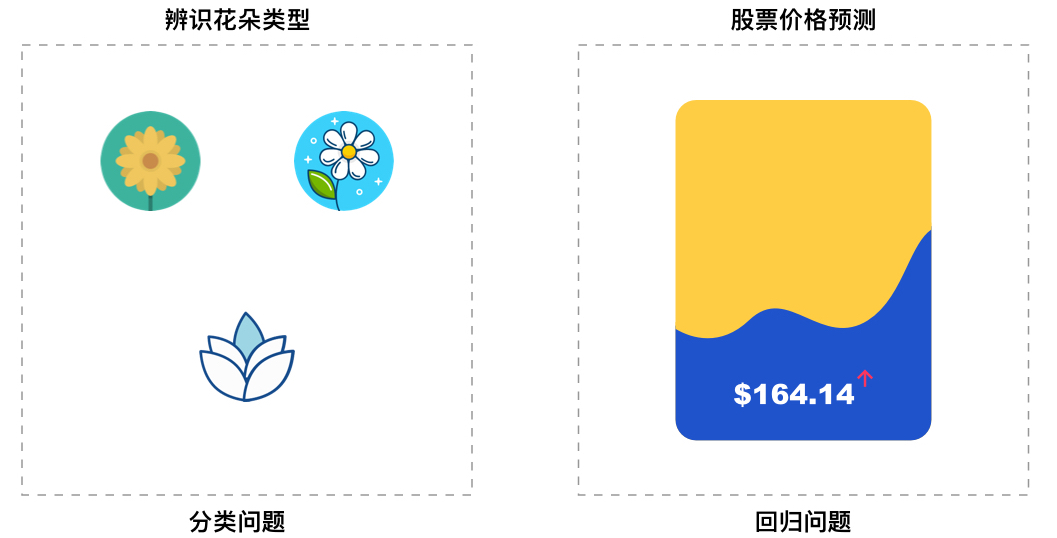
通过上面的小例子,你应该对「监督学习」有一定印象了。而类似于上面这种识别类别的问题,我们一般称之为监督学习的分类问题。分类其实是一种最常见的问题类型,例如:动物的种类判断、植物的种类判断、各类物品的种类判断等。
除了分类问题,监督学习中还有十分重要的一类,那就是回归问题,这也就是本周需要学习的内容。首先,回归问题和分类问题一样,训练数据都包含标签,这也是监督学习的特点。而不同之处在于,分类问题预测的是类别,回归问题预测的是连续实数值。
例如,股票价格预测,房价预测,洪水水位线预测,这都是机器学习回归问题。因为我们需要预测的目标都不是类别,而是实数值。
无监督学习介绍
在监督学习的介绍中,我们曾经引用了著名机器学习专家 Mehryar Mohri 的叙述。其强调了,当监督学习算法去数据集中积累经验时,很关键的一点在于训练数据集是有标签的。数据带有标签用通俗的话来讲,就是我需要告诉算法这个是房子,这个是人,这个是花,然后它就慢慢学会认识这些事物了。
但是,生活中我们遇到的大部分数据它是没有标签的。真的,如果你留意的话,你会发现无标签数据相对于有标签数据要多很多,为什么呢?
因为给数据添加标签是一个十分繁重的工作呀!你在监督学习中用到的鸢尾花数据集、手写字符数据集都是需要人工去添加标签的。想想如果需要给几十万、上百万的数据添加标签,需要多大的工作量?
不过,面对无标签数据,我们还有一类机器学习方法叫做无监督学习。
无监督学习示例
无监督学习 是面对无标签数据常常使用的一类机器学习方法,而通常我们用得较多的就是数据聚类。
数据聚类,形象的介绍就是把一堆数据按照它们特征的相似度分为多个子类。例如,我们手中有一个花朵数据集,包含有叶片长度和宽度两个特征。我们可以根据这两个特征将其在二维平面中可视化。

如上图所示,你通过肉眼就能发现,全部数据很明显呈现出 2 个不同的类别(簇)。这也就说明,我们的数据集中很大可能是采集了来自于 2 种花的特征。此时,如果你知道该数据集的特征来自于哪两种花,我们就可以迅速的完成数据标记,给整个数据集打上标签。也就是说,可通过聚类的手段,给无标签数据集添加标签。

所以说,无监督学习的「力量」是很大的,它不仅可以用于数据的聚类,同时还能帮助我们给数据集添加标签。于是,很多机器学习的流程其实就变成了:

当然,数据聚类只是无监督学习中的主要任务。无监督学习实际上还包括数据降维、图分析、关联规则分析等。
线性回归
介绍
线性回归是一种较为简单,但十分重要的机器学习方法。掌握线性的原理及求解方法,是深入了解线性回归的基本要求。除此之外,线性回归也是监督学习回归部分的基石,希望你能最终掌握机器学习的一些重要的思想。

如上图所示,不同的房屋面积对应着不同的价格。现在,假设我手中有一套房屋想要出售,而出售时就需要预先对房屋进行估值。于是,我想通过上图,也就是其他房屋的售价来判断手中的房产价值是多少。应该怎么做呢?
我采用的方法是这样的。如下图所示,首先画了一条红色的直线,让其大致验证数据色点分布的延伸趋势。然后,我将已知房屋的面积大小对应到红色直线上,也就是蓝色点所在位置。最后,再找到蓝色点对应于房屋的价格作为房屋最终的预估价值。

在上图呈现的这个过程中,通过找到一条直线去拟合数据点的分布趋势的过程,就是线性回归的过程。而线性回归中的「线性」代指线性关系,也就是图中所绘制的红色直线。
此时,你可能心中会有一个疑问。上图中的红色直线是怎么绘制出来的呢?为什么不可以像下图中另外两条绿色虚线,而偏偏要选择红色直线呢?

绿色虚线的确也能反应数据点的分布趋势。所以,找到最适合的那一条红色直线,就成为了线性回归中需要解决的目标问题。
通过上面这个小例子,相信你对线性回归已经有一点点印象了,至少大致明白它能做什么。接下来的内容中,我们将了解线性回归背后的数学原理,以及使用 Python 代码对其实现。
一元线性回归
上面针对 线性回归 的介绍内容中,我们列举了一个房屋面积与房价变化的例子。其中,房屋面积为自变量,而房价则为因变量。另外,我们将只有 1 个自变量的线性拟合过程叫做一元线性回归。
下面,我们就生成一组房屋面积和房价变化的示例数据。x为房屋面积,单位是平方米; y为房价,单位是万元。
import warnings |
import numpy as np |
示例数据由 10 组房屋面积及价格对应组成。接下来,通过 Matplotlib 绘制数据点,x, y 分别对应着横坐标和纵坐标。
from matplotlib import pyplot as plt |
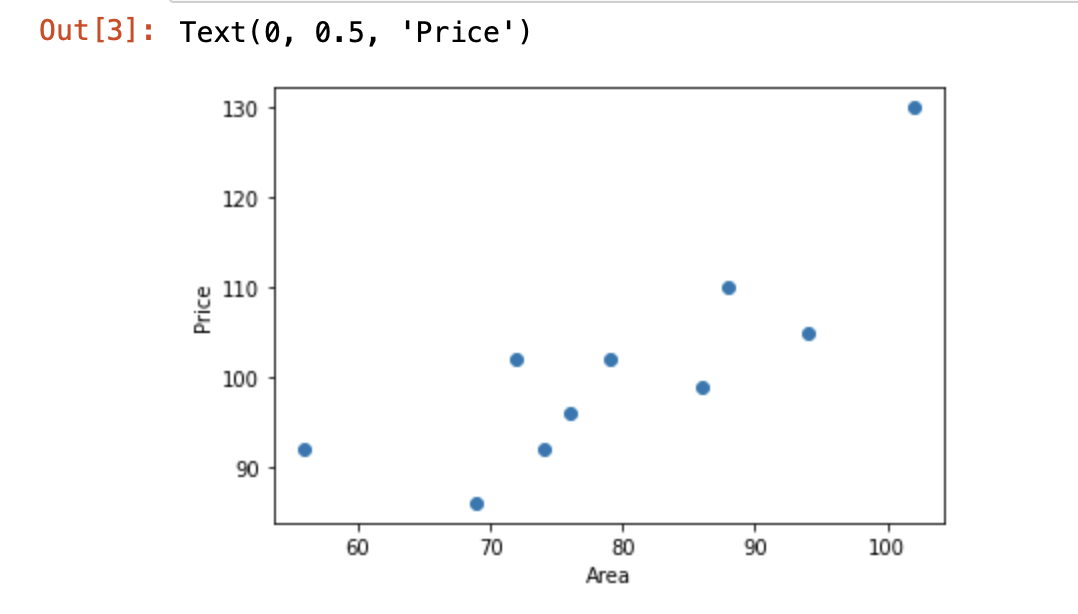
正如上面所说,线性回归即通过线性方程去拟合数据点。那么,我们可以令该 1 次函数的表达式为:
$$
y(x, w) = w_0 + w_1x \tag{1}
$$
$$
公式 (1) 是典型的一元一次函数表达式,我们通过组合不同的 w_0 和 w_1 的值得到不同的拟合直线。
$$
接下来,对公式 (1) 进行代码实现:
def f(x: list, w0: float, w1: float): |
那么,哪一条直线最能反应出数据的变化趋势呢?
想要找出对数据集拟合效果最好的直线,这里再拿出上小节图示进行说明。如下图所示,当我们使用 �(�,�)=�0+�1� 对数据进行拟合时,就能得到拟合的整体误差,即图中蓝色线段的长度总和。如果某一条直线对应的误差值最小,是不是就代表这条直线最能反映数据点的分布趋势呢?


